


In this blog, we will learn some more complex commands used in a Redis database server.
Prerequisite:
Check my previous blog for a better understanding.
Link: https://hashnode.com/edit/clo040pt9000509l4cwq4cuyq
Redis is a data structure server. At its core, Redis provides a collection of native data types that help you solve a wide variety of problems, from caching to queuing to event processing.
Some important commands to remember:-
Use command "select 1" to select database 1.
Use command "select 0" to go back to the default database 0.
Use command "keys *" to show all available keys.
Use command "flushall" to delete all data.
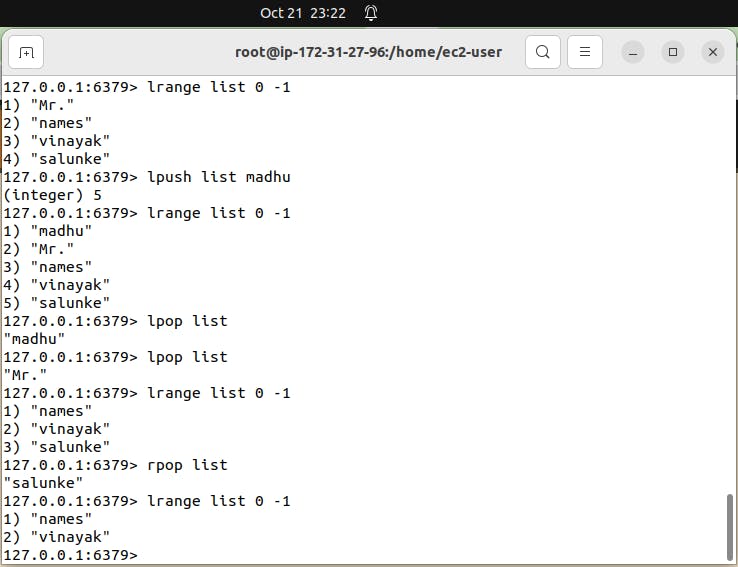
Similarly to check the contents in list data type use command "lrange"
lrange list 0 -1 command to show all data in list data type key-name is list.
Data types in the Redis server
Data types in Redis servers are different ways of storing and organizing data in memory. Each data type has its own commands and features that make it suitable for different use cases.
Data types:
1. String:
A string is a sequence of bytes that can store any kind of data, such as text, numbers, images, etc.
Commands used to manipulate the string data are as below:
Use command SET key-name vinayak
Explanation= You can use the command SET key-name vinayak to store the value "vinayak" under the key "key-name".
Use command GET key-name.
Explanation= You can use the command GET key-name to get the value of "key-name".
Use command APPEND key-name "additional"
Explanation: This command appends the value “additional” to the existing value of “key-name”.
Use command STRLEN key-name
Explanation: STR means string and LEN means length. This command returns the string length of the value of “key-name”.
Use command SETNX key-name vinayak
Explanation: This command sets the value of “key-name” to “vinayak” only if “key-name” does not exist already. SET means to set, N means to Not and X means exists. Set if not already exists.
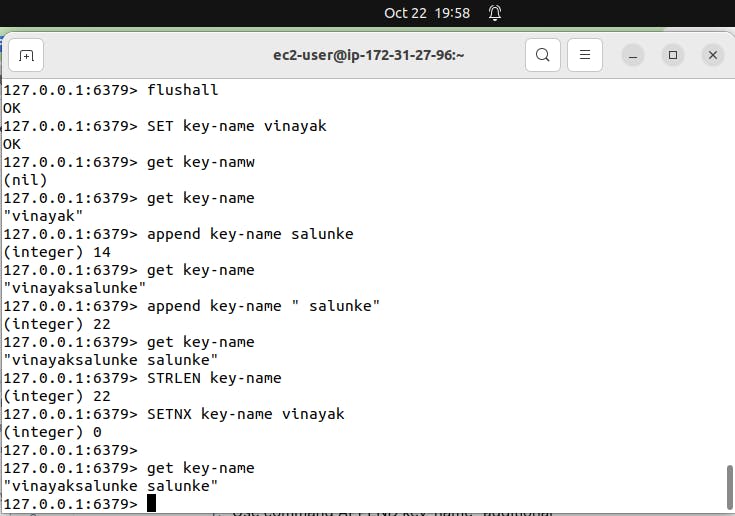
Use command SETEX key-name 10 vinayak
Explanation: This command sets the value of “key-name” to “vinayak” and sets “key-name” to timeout after 10 seconds.
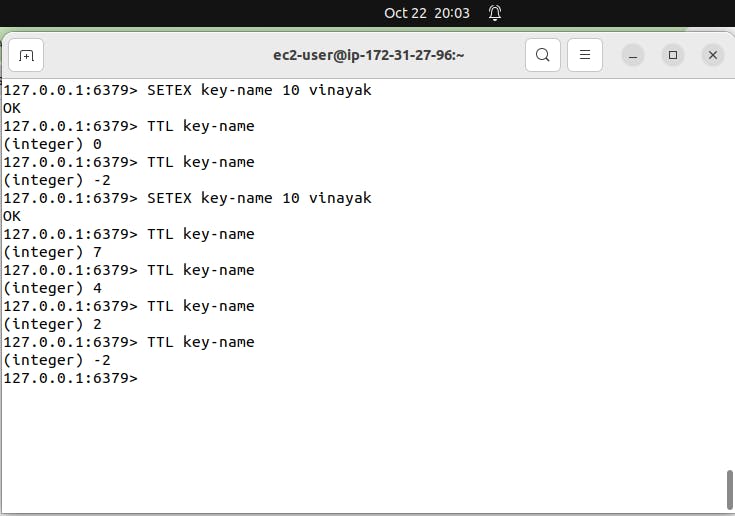
Use command INCR key-name
Explanation: This command increments the integer value of “key-name” by one.
Use command DECR key-name
Explanation: This command decrements the integer value of “key-name” by one.
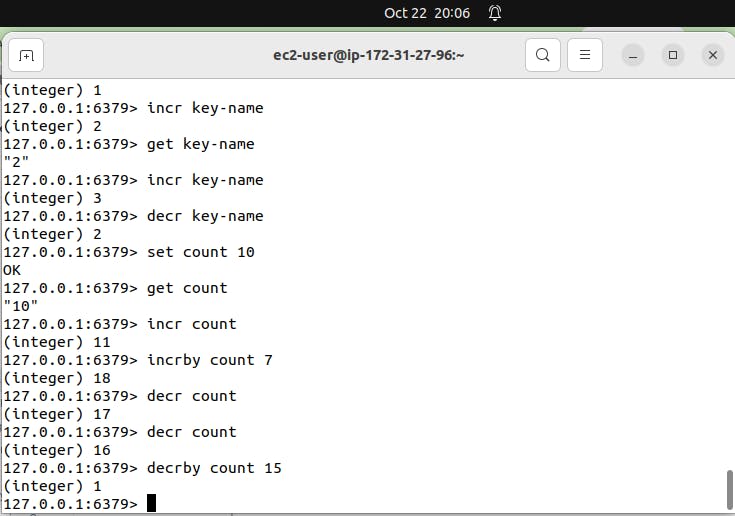
Use command MSET key1 vinayak1 key2 vinayak2
Explanation: This command sets multiple string-type keys to multiple values.
Use command MGET key1 key2
Explanation: This command gets the values of all specified keys
del key-name >> To delete or remove the string type key named key-name.
2) Hashes:
A Redis hash is like a small database within a database. It’s a collection of field-value pairs, similar to a row in a table of a relational database where each field (column) is associated with a value. Redis hashes are a data type that can store a mapping between a string field and a string value.
For example, let’s say we have a hash named “student”. This hash could represent a student in a school database. The fields could be “name”, “age”, “grade”, and “subject”, and the values could be “Vinayak”, “15”, “10”, and “Mathematics” respectively.
Here’s how you can use commands to manipulate this hash data type in redis:
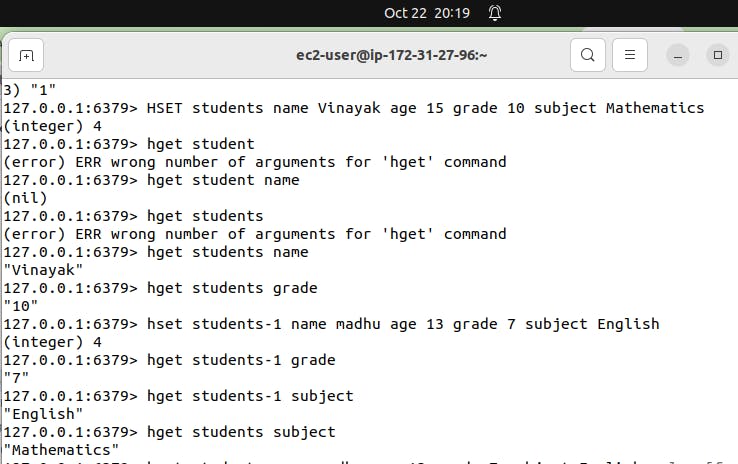
Use command HSET students name Vinayak age 15 grade 10 subject Mathematics
Explanation: This command sets the fields and their corresponding values in the hash “students”. It’s like filling out the details for a student in a school database.
hset students-1 name madhu age 13 grade 7 subject English
Use command HGET student name
Explanation: This command retrieves the value of the field “name” from the hash “students-1”. It’s like asking, “What’s the name of this student?”
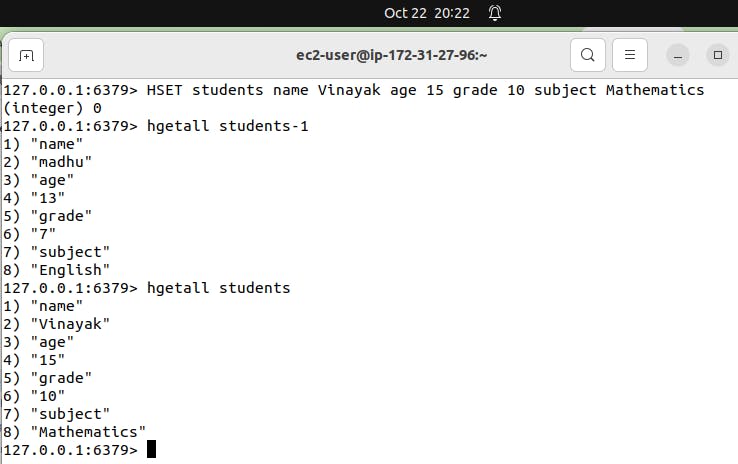
Use command HGETALL student
Explanation: This command retrieves all fields and their values from the hash “student”. It’s like asking, “Can you give me all the details of this student?”
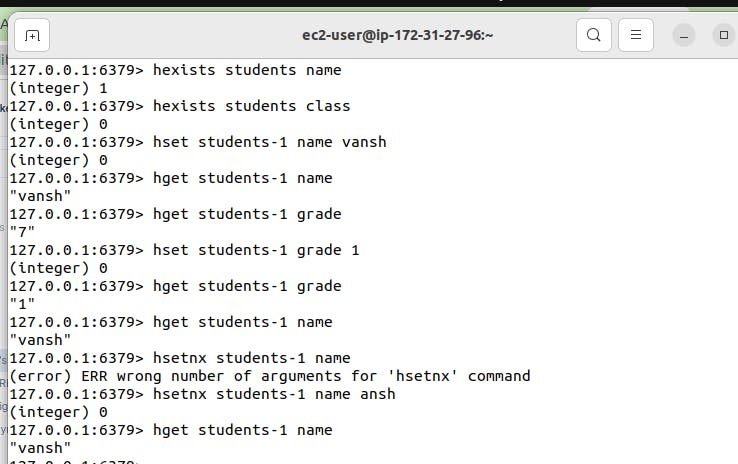
hexists students name
Explanation: This command will check in hash named 'students' name field exists or not. If it exists then output will be '1' and if it doesn't then output will be '0'
hset students-1 name vansh
This will override the the name in students-1 hash.
To avoid override we can use
hsetnx students-1 name ansh
This will check value already exists or not. If it already exists then it will not write anything.
hsetnx students-1 division B >> If field is new (not already exists) then it will add data.
hkeys students >> To get only keys in students hash.
hvals students >> To get only values in students hash.
hmget students name grade >> m=multiple To show multiple values of name and grade field.
hlen students >> to get the length of the hash.
del students >> To delete or remove the hash type key named students.
3) lists
Redis supports lists, which are like ordered collections of items. You can use RPUSH to add items to the end of a list and LPUSH to add items to the front. With Redis, you don't need to create a list first; you can use these commands directly. If a list becomes empty, Redis removes it automatically. This makes managing data in Redis simple and efficient.
Some of the important commands for interacting with lists are:
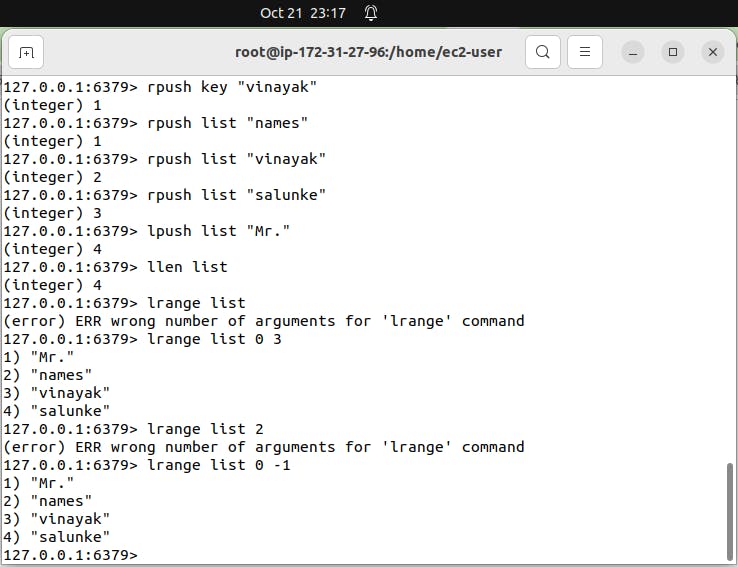
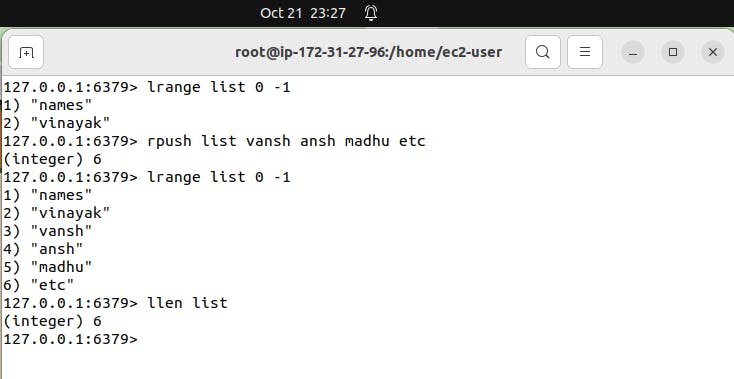
RPUSH: Use RPUSH to add an item to the end of a list. It's like adding an item to the back of a line.
LPUSH: LPUSH is used to insert an item at the start of a list. Think of it as adding an item to the front of a line.
LLEN: LLEN tells you how many items are in a list. It's like counting the number of people in the line.
LRANGE: LRANGE lets you fetch items from a list within a specific range. It's like grabbing a few items from the middle of the line.
It gives a subset of the list. It takes the index of the first element you want to retrieve as its first parameter and the index of the last element you want to retrieve as its second parameter. A value of -1 for the second parameter means to retrieve elements until the end of the list, -2 means to include up to the penultimate, and so forth.
LPOP: LPOP removes and retrieves the first item from a list. It's like taking the first person out of the line.
RPOP: RPOP does the same but from the end of the list, like removing the last person from the line.
lset list 5 anu this command will check list key and 5th index of it. If 5th index is already present then it will change it to anu. Here in place of etc "anu" will get added.
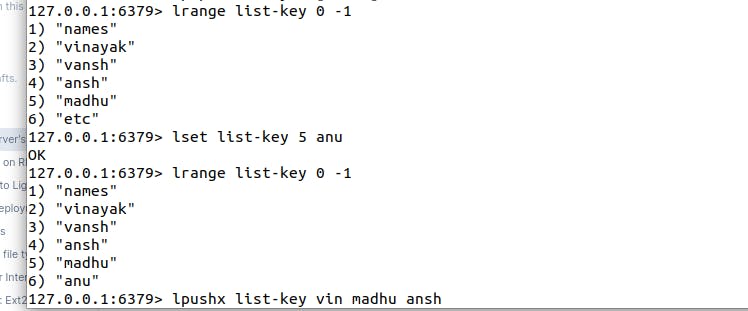
lpushx will check list-key already exists (x) or not. If list-key is not already exists then command will not write any data.
Example:
lpushx list-key-1 vin madhu ansh
If list is not already exists then command will not write any data. If key exists then it will add data in that key.
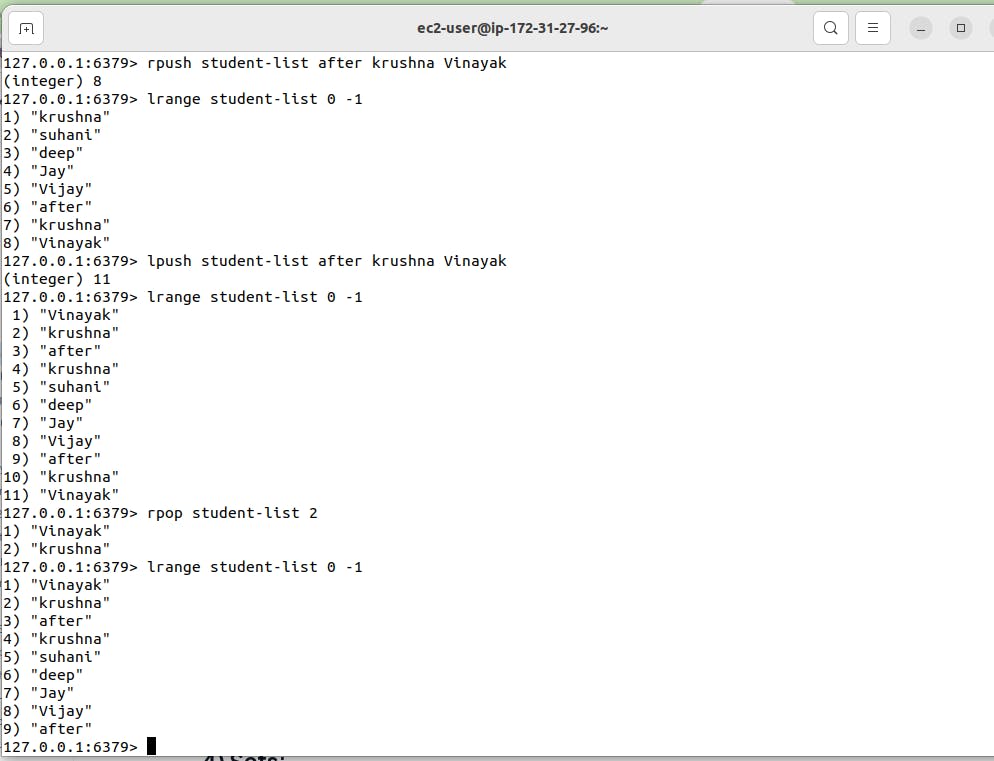
lpush student-list Jay deep suhani krushna >> This command will add data in student-list key.
linsert student-list after Jay Vijay >> This command will add Vijay after Jay in the student-list.
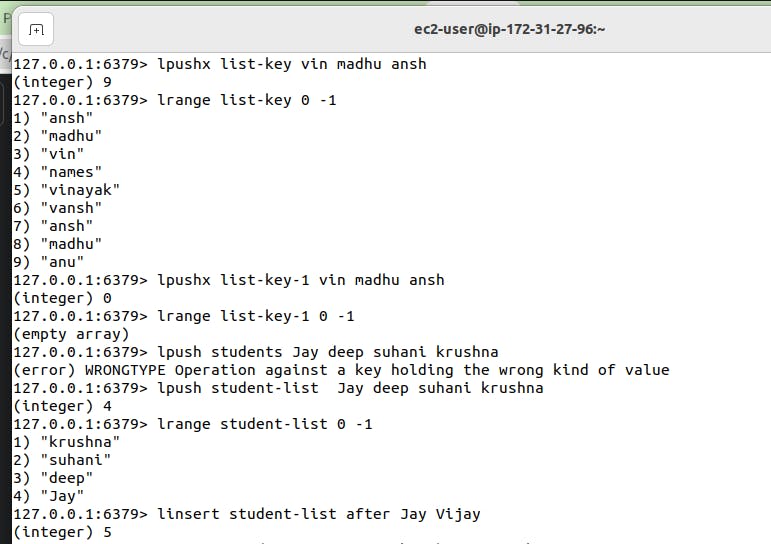
Similarly we can use rpush to add data in right. R means at right side of list.
rpop to delete data from right side. r means from right side.
4) Sets:
Explanation: Redis Sets are collections of unique and unordered values. They are used to store a group of distinct items.
Analogy: Imagine a set of playing cards. Each card is unique, and you can't have duplicates. Redis Sets are like this collection of unique cards, and you can perform operations like checking which cards are in the set.
Commands in set:
sadd command to add set. s means set and add means to add.
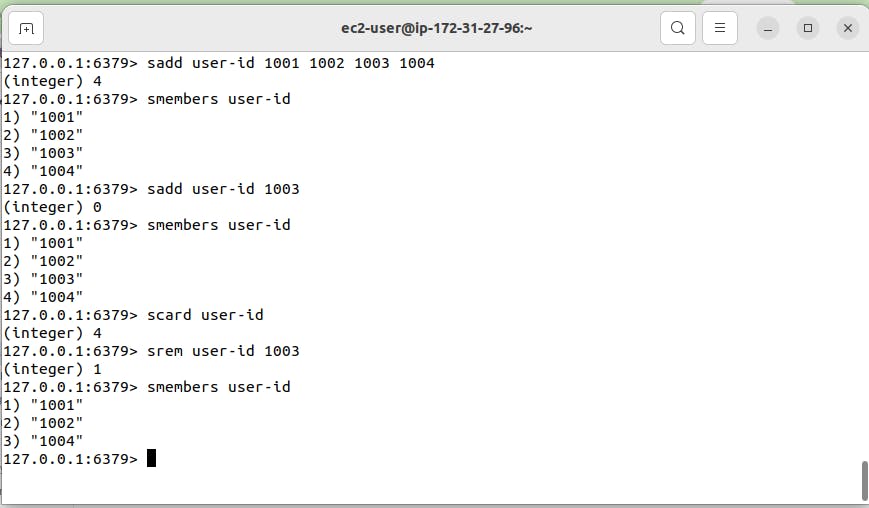
sadd user-id 1001 1002 1003 1004 >> This will add set named user-id with mentioned data in it.
If the element we try to add is already inside, then 0 is returned, otherwise SADD returns 1:
smembers user-id >> smembers command to check data in set. "s" means set and "members" means what are the members in the set, show all.
Set is unique and unordered collection of data means it doesn't allow duplicate value. If in above example we write 1003 two times then only one 1003 will get added as it accepts unique values.
This data type is best suit for user-id or tokens or coupon etc.
scard user-id >> This will show how many members are present in the set.
srem user-id 1003 >> To remove the 1003 user-id from the set. "s" means set and "rem" means remove.
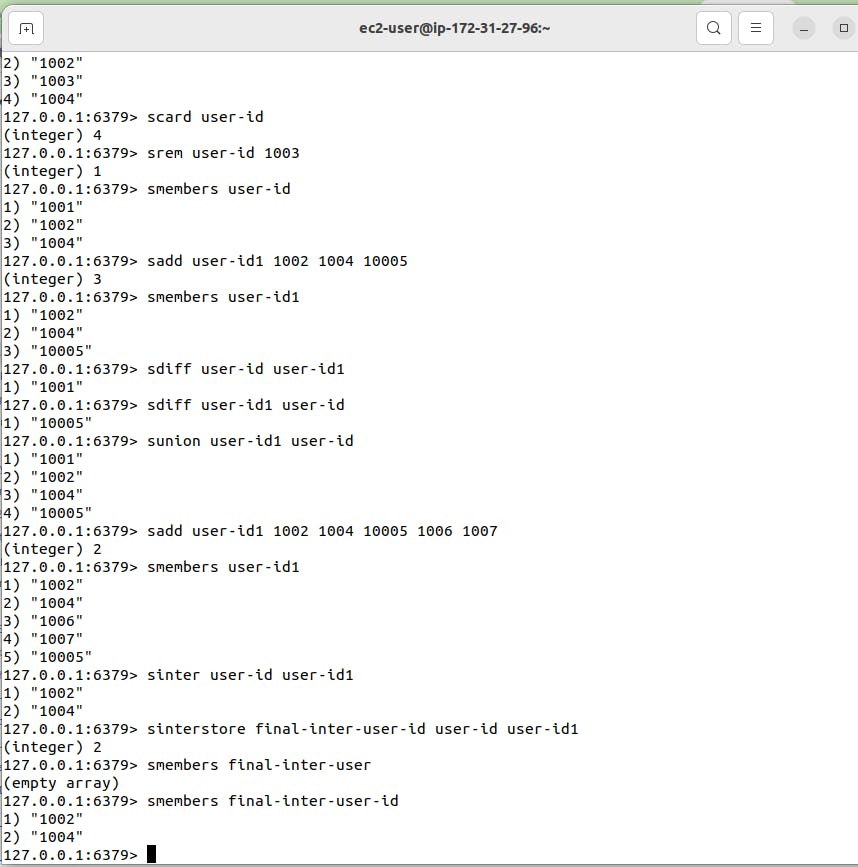
sadd user-id1 1003 1004 10005
sdiff user-id user-id1 >> This command will show difference between user-id set and user-id1 set.
sunion command will add (union) both sets.
sunionstore final-user-id user-id user-id1
This will add both user-id and user-id1 and store data in new final-user-id.
sinter user-id user-id1 >> command will show intersection means common data in both sets. "
sinterstore final-inter-user-id user-id user-id1 >> This will store the result of intersection in new set final-inter-user-id set.
SISMEMBER tests if the given value is in the set. It returns 1 if the value is there and 0 if it is not.
5) sorted Sets:
Sets are a very handy data type, but as they are unsorted they don't work well for a number of problems. This is why Redis 1.2 introduced Sorted Sets.
A sorted set is similar to a regular set, but now each value has an associated score. This score is used to sort the elements in the set.
Explanation: In this members are sorted on the basis of scores. It helps in scoreboard in cricket matches. Or in rewards points to sort the members on the basis of their scores.
Redis Sorted Sets are like Sets but with an associated score for each member. They maintain an ordered list of elements based on their scores.
Analogy: Think of a leaderboard in a game where each player has a score. Redis Sorted Sets are like this leaderboard, helping you rank players based on their scores.
Commands in sortedset:
zadd run 100 vinayak
zadd is a command to add data in sorted set. run is key and 100 is a score. Vinayak is a member in sorted set.
zrange run 0 -1 >>Command to show all members.
zrange run 0 -1 withscores >>This command will show all members with their scores.
zadd run 200 Sandip 300 Pradip 150 atul >> This will add data in sortedset named run.
zrange run 0 -1 withscores >> This will show all members with scores in sorted order.
zcard run >> This command will show number of members in sortedset.
zcount run 100 300 >> This will show the count of total members whose scores are in between 100 to 300.
zacore run Sandip >>To check the score of member Sandip.
zrank run Pradip >> This will show rank of Pradip in the cricket scoreboard 🏏.
zrangebyscore run 100 300 withscores >> This will show the members whose scores are in between 100 to 300.
zrem run vinayak >> This command will remove the member vinayak from run sortedset.
Short summary of Redis data types::
Strings: Redis strings are the most basic data type and represent a sequence of bytes. They are used for a wide range of purposes.
Lists: Redis lists are collections of strings sorted by their insertion order. They are often used for tasks like queuing and task management.
Sets: Redis sets are unordered collections of unique strings. They allow for fast operations such as adding, removing, and testing for existence.
Hashes: Redis hashes are like dictionaries or maps and store field-value pairs. They are useful for modelling structured data.
Sorted Sets: Redis sorted sets are collections of unique strings sorted by their associated scores. They are commonly used for leaderboards and ranking systems.
Streams: Redis streams act as append-only logs, allowing you to record and process events in the order they occur.
Geospatial Indexes: Redis geospatial indexes are used for finding locations within a given geographic area.
Bitmaps: Redis bitmaps enable bitwise operations on strings, often used for building data structures like Bloom filters.
Bitfields: Redis bitfields efficiently encode multiple counters in a string value and support atomic get, set, and increment operations.
HyperLogLog: Redis HyperLogLog provides probabilistic estimates of the cardinality of large sets. Meaning= Redis HyperLogLog is a tool that can give you an approximate answer to the question of how many different elements are in a large collection of data, without using too much memory or time.
These data types offer a wide range of capabilities for different use cases, from caching and queuing to event processing.
If you find the blog helpful, please do like it and share it with your friends. If you have any doubts or questions related to the topics covered in the blog, feel free to ask them in the comments section. I'll be more than happy to help! 😊👍👥